「深層学習 Ubuntu 24.04 に Tensorflow GPU をインストール」
でソフトウェア環境を新しくしたので、この環境で TensorFlow HUB を試してしました。
TensorFlow HUB は学習済みモデルのリポジトリで、tensorflow_hub ライブラリを使用して最新の学習済みモデルをダウンロードして利用します。
TensorFlow HUB スタートガイド(公式ページ)
https://www.tensorflow.org/hub/tutorials?hl=ja
(1) TensorFlow HUB インストール
TensorFlow HUB インストール(公式ページ)
https://www.tensorflow.org/hub/installation?hl=ja
仮想環境にインストール
(.venv):~/pytorch/tf$ pip install “tensorflow>=2.0.0”
(.venv):~/pytorch/tf$ pip install –upgrade tensorflow-hub
(2) チュートリアルのオブジェクト検出サンプルプログラムを実行
チュートリアル オブジェクト検出(公式ページ)
https://www.tensorflow.org/hub/tutorials/object_detection?hl=ja
基本的には、Jupyter notebook でチュートリアルのソースをコピーして実行すれば動きます。
(インストールされていないモジュールについてはインストールなどが必要です。)
まず「セットアップ Imports and function definition」のソースを実行してみましたが、モジュール無しエラー”ModuleNotFoundError: No module named ‘matplotlib'” が出ましたのでインストール。
(.venv):~/pytorch/tf$ pip install matplotlib
インストール後に Imports and function definition サンプルソースコードを実行
実行結果(一部抜粋)——————
2.20.0
The following GPU devices are available: /device:GPU:0
————————–
TensorFlowのバージョンと利用可能な GPU の表示が問題なく出力されました。
「使用例」以降のソースをコピーして Jupyter notebook で実行して、殆どはそのままで動きました。
この環境では、サンプル画像のダウンロードで “HTTP Error 403” の HTTPError エラーが発生しましたが、とりあえずサンプル画像を手動でダウンロードしてローカルからの読み込みにしました。
画像はウィキメディア・コモンズから獲得
https://commons.wikimedia.org/wiki/File:Naxos_Taverna.jpg
サンプルソースコードの
image_url = “https://upload.wikimedia.org/wikipedia/commons/6/60/Naxos_Taverna.jpg”
の部分を
image_url = “file:///home/(user)/pytorch/tf/Naxos_Taverna.jpg”
に修正して実行
このページのサンプルソースコードでは openimages_v4/inception_resnet_v2/1 のモデルを指定しています。
module_handle = “https://tfhub.dev/google/faster_rcnn/openimages_v4/inception_resnet_v2/1”
参考:モデルのページ
https://www.kaggle.com/models/tensorflow/inception-resnet-v2
参考:openimages_v4のページ
https://storage.googleapis.com/openimages/web/download_v4.html
ダウンロードした画像で推論実行結果(Jupyter notebookで実行した結果です。)
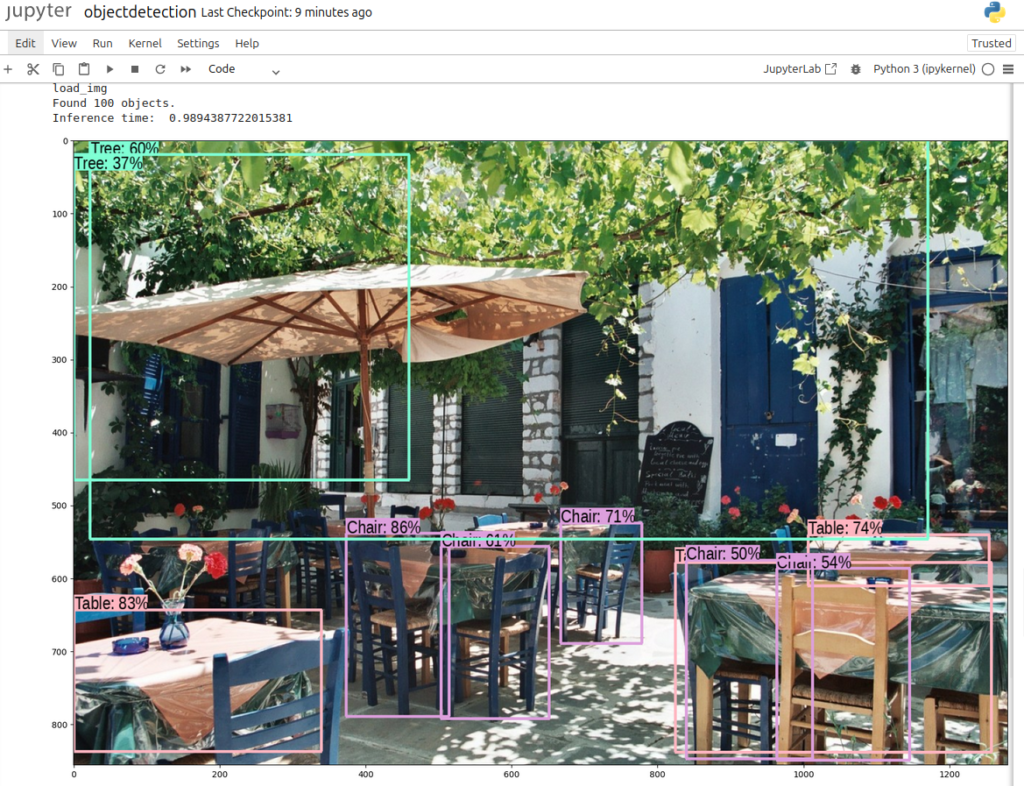
ほぼサンプルソースコードの通りで実行できました。
(3) サンプルプラグラムの応用
チュートリアルを参考にして、フォルダ内の画像ファイルからの特定の動物(とりあえずクマ)の検出を行う簡単な Python サンプルプログラムを自作してみました。
(練習のためのサンプルプログラムです。詳細の動作確認は行っていません。)
Pythonプログラム(テキストファイル UTF-8)
tf_od_pic_sample.py
このプログラムは、画像ファイルのあるディレクトリを選択して画像ファイルを順次読み込みオブジェクトを検出、推論結果で該当するクラスのある画像にはバウンディングボックスを描画して画像ファイル出力します。
ソースコードの以下の部分でモデルで定義されたクラス名を指定しています。
# 対象のクラス
# 必要に応じて学習済みモデルのクラス名を指定
# クマ
TARGET_CLASSES = [ “Bear”, “Brown bear” ]
ここでは Bear(クマ一般)、Brown bear(ヒグマ)を指定しています。
(その下にコメントとして、動物関連のクラス名一覧を記述しておきました。)
下記のようにオブジェクト検出結果のクラスから必要な部分のみを対象とするロジックを加えています。
class_name = class_names[i].decode(“ascii”)
if (scores[i] >= min_score) and (class_name in TARGET_CLASSES) :
出力ディレクトリは、入力ファイルディレクトリの配下に作成されます。(ディレクトリ名:detected+(数字))
実行例)
画像のあるディレクトリ
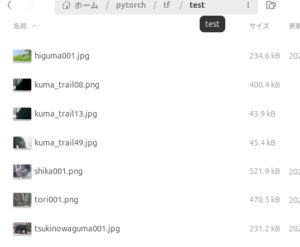
テストに使用した画像は、PhotoAC フリー素材サイトからダウンロードしたヒグマとツキノワグマの画像、トレイルカメラ(「トレイルカメラ(2) 野生動物の観察1」)の映した(おそらく)ツキノワグマの一部と、シカ、鳥の画像です。
ディレクトリ選択
実行結果
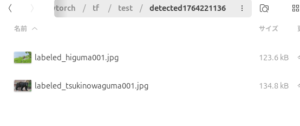
出力された画像
ヒグマ

ヒグマは上手く検出されました。
ツキノワグマ

学習済みモデルで特に「ツキノワグマ」のクラスは無いですが、全身が映った画像では Brown Bear 88%, Bear 61% として検出されました。
以下のようなクマ画像のうち体の一部のみが映った画像では正常に検出されませんでした。



これらの画像は人間が目視してもわかりにくいと思います。
今回のテストで使用した画像ファイルの一部はトレイルカメラ(「トレイルカメラ(2) 野生動物の観察1」)の映した(おそらく)ツキノワグマの一部をキャプチャしたものです。
人間が判別するなら一連の動きから総合的判断で(おそらく)クマと分かる思いますが、単純なオブジェクト検出モデルの場合だと判断が難しい場合もあると思います。
応用例として、カメラで動物を検出して通報等をするシステムを構築するなどの場合は、より精度を高めるならば、単純な画像だけでなく動きを考慮したアルゴリズムかニューラルネットワークの工夫(行動認識モデルなど)や体の一部でも判別できる学習なども必要になるかもしれません。
(S.Onda 2025/11/27-28)

{kind=link}